 Fraunhofer Institute for High-Speed Dynamics, Ernst-Mach-Institut, EMI
Fraunhofer Institute for High-Speed Dynamics, Ernst-Mach-Institut, EMIDigital Engineering @ Fraunhofer EMI
Applied Research Portfolio
Data-Driven Design
- Behavioural Prediction
- Decision Support
- Explainability
- Hybrid AI
Data Processing and Analytics
- Fusion and Augmentation
- Dimensional Reduction
- Knowledge Extraction
- Rule Mining
- Visualization
Data- & Knowledge Engineering
- Process Modeling
- Ontologies and Semantics
- Knowledge Graphs
- Decentralized Data Spaces
- Digital Traceability
Example solutions
Grey-Box-Processing – A novel method to efficiently validate and optimize simulation models
In order to exploit valuable experimental data to the fullest, this method uses Gaussian processes to deeply integrate sparse, heterogeneous measurement data with numerical simulation data to identify deviations while accounting for anisotropic uncertainties. Deviations are represented by physical – and thus interpretable - interactions between a virtual representation of the experimental observations (virtual boundary conditions) and the original model behavior. By interpreting the temporally resolved interaction parameters (e.g. forces or energies) one can quantify the deviations comparably and get clear directions on how to improve the representative qualities of any simulation model.

- Automatically process and augment complex, heterogeneous and sparse measurement data
- Quantitatively assess deviations with hybrid datasets and physically interpretable parameters
- Apply to measurement and purely simulation-based data to optimize model performance
Adaptive Training Data Generation – A pipeline to efficiently generate information-dense training data for machine learning engineering applications
While there is significant potential in data-driven methods, in engineering applications, training data is usually scarce, complex and expensive. For our machine learning (ML) applications, we follow a data-centric approach focusing on engineering the training data and its information content while employing well-proven ML model architectures. The goal is to reduce the (simulation) resources needed to generate training data sets which maximize the representation of the system’s behavior and their sustainable reusability in multiple training scenarios. This data generation pipeline uses ML model performance (prediction error metrics) and expert-based criteria to dynamically and automatically adapt the process of sampling additional points in the design space. This pipeline and its adaption criteria can be designed to generate representative and reusable core data sets as well as to specifically tailor such core data sets for a particular ML application.
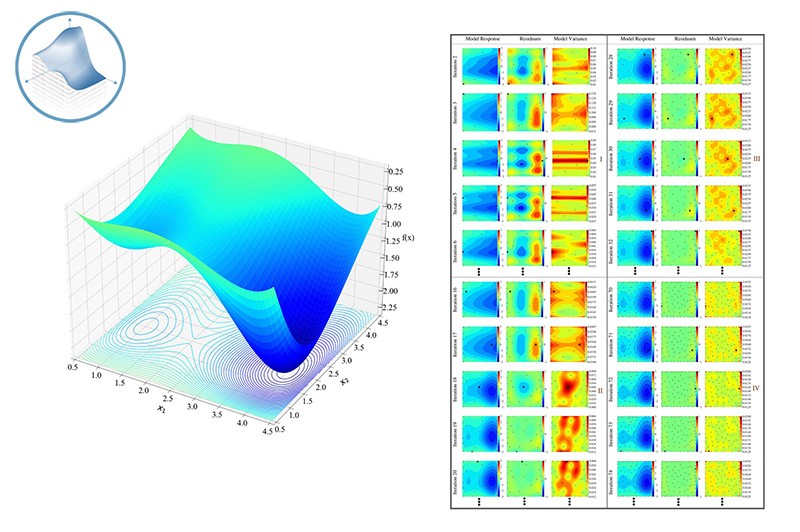
- Use model performance and expert-based criteria to adaptively optimize training data
- Automatically adapt the generation of training data to optimize simulation resource efficiency
- Maximize the representative characteristics of the dataset to improve ML performance and reusability
Distributed Data Spaces – Link digital engineering assets along process and value chains
Connect the dots to reveal the big picture: Engineering processes mostly involve several partners holding valuable data and information. Semantically structured meta-data makes digital assets (e.g. data or models) interoperable and ready to be integrated into a graph-based “fabric of knowledge”. We demonstrate the use of linked data to inform decisions about materials processing routes and structural design in the additive manufacturing domain. Well-established data space technology (e.g. IDS resources) provides for scalable infrastructures and data sovereignty for each partner. The traceability of data and information equally valuable for comprehensive sustainability analyses of products and processes.
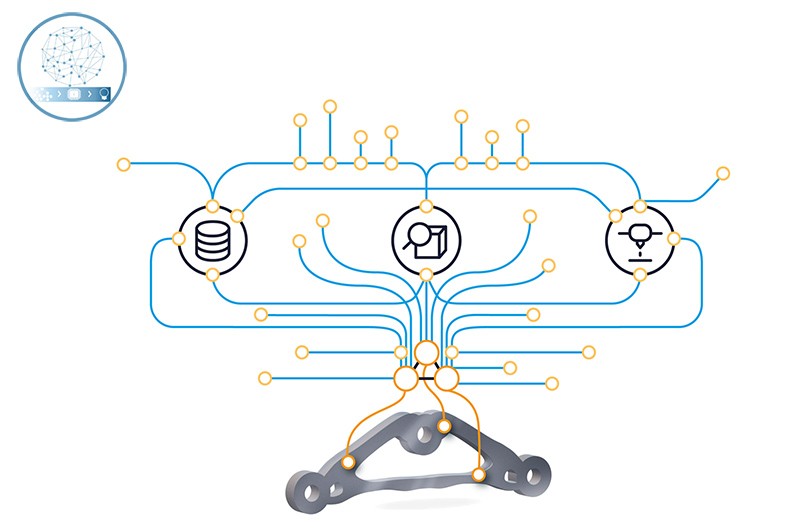
- Link data and information along processes to comprehensively optimize for performance, sustainability or resilience
- Enable new business models and stay sovereign by making your digital assets FAIR (Findable, Accessible, Interoperable, Reusable)
- Ensure sustainable data and knowledge management using semantic technologies
Example projects
DigiTain – Digitalization for Sustainability
ATTENTION – artificial intelligence for real-time injury prediction
Forschungsprojekt AIMM - Fraunhofer EMI
X-ray car crash – crash test under x-ray - Fraunhofer EMI
AIMM-Project — Systemizing the load case definition for component tests
List of publications
‘Grey-Box-Processing’: a novel validation method for use in vehicle safety applications
FISITA Library | Visualisation of body deformation during collision using X-rays
TC-journal | Datenbasierte kommunale Resilienzbewertung in Krisen
ISWC2022| OAEI2022: Results of the Alignment Evaluation Initiative 2022
wt Werkstattsechnik online| Leichtbau: Datenvernetzung für additive Fertigung
Fraunhofer MATERIALS | Erste MDS-Implementierung
Konzept zur Digitalisierung der Datenverarbeitung aus werkstoffwissenschaftlicher Forschung